这篇文章是目前进行图像实例分割的state of art,由于近期在刷kaggle上的WAD比赛,需要完成实例分割的任务,所以小刷了几篇论文,这是概述。
历史
文章的开始自己也阐明了,其实本文提出的网络(PANet)在架构上并没有很大的创新,更多的是对去年扛把子何恺明组提出的Mask RCNN架构上进行的一些修改,不过考虑到毕竟是在原有网络的基础上有提升,而且文章也非常厚道地将很多对架构的思考加了进去,还是值得稍作分析的。
动机
在文章开头的Our findings中提了三个原来Mask RCNN中的问题:1)在低层中提取的特征还是对大物体的实例分割有帮助的。但是在Mask RCNN中(此处主要是使用了FPN的Mask RCNN),由低层到最高层的特征路径很长,使得获得准确的定位信息的难度增大;2)proposal都是从单层中提的,没有考虑到其他层的混合信息;3)确认mask时只用了某个视窗内的信息(反卷积感受野带来的问题)
贡献
接下来当然就是讲述本文的贡献blah blah blah。针对以上的三个问题,文章分别给出了自己的解决方法:1)你不是从底到顶路径长么?我给你反过来augment一下,这样路径不就短了么;2)你不是只用了单层信息么?我发明个自适应池化,把几层都用上;3)你不是只用了某个视窗内的信息么?我给你上个全连,把能连的都连上。这基本也就总结了本文的几大突出贡献,反正都是对症下药,没做任何无病呻吟的事。ok,那闲话少叙,我们直入正题,这几种方案都是怎么实现的呢?
1. 反向augment
对FPN如数家珍的同学应该对它其中采用的topdown augment印象深刻,因为这思路简单粗暴,强行通过卷积对各层进行尺度变化后再混合,达到了一人信息天下晓的程度。对于将顶层信息沉淀至低层带来的方便自是不必多说,原来需要跨过100多层的信息现在就通过3层卷积就到地方了。但是不幸的是由于设计的augment是单向的,导致在另外一个方向上低层信息想要到顶层没有任何简化途径,还是要跨过原始的模型–也就是说还是100多层。导致这一问题的原因非常简单,augment是topdown的,所以解决方案更简单,我再给你加个bottomup的不就完了么?这篇文章也正是这样做的,这样也就保证了提取出的5层的信息也能够包含低层信息,这样在5层上提取proposal的时候就能够得到更好的边界定位效果(因为低层信息对定位有帮助)
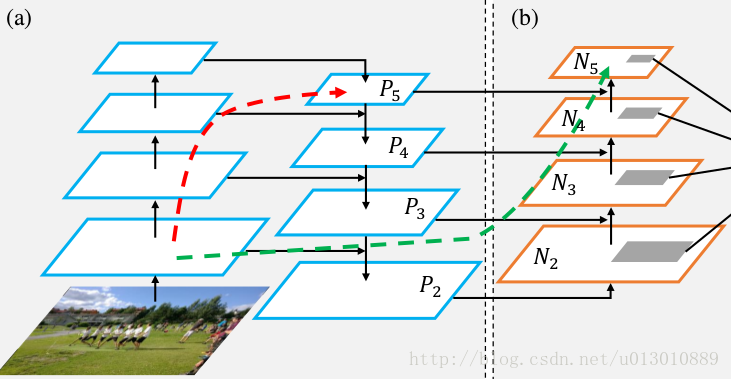
2. 自适应池化
特征做了bottomup的augment之后,如果按照FPN的解决方案,直接在各个层级上面提取proposal就ok了,但是前面我们已经讲过,这样在提取proposal的时候就只用到了单层信息,为了得到更好的提取proposal的精度,我们有必要将几层的信息结合起来。正是基于这一点考虑,PANet从4个层对应地做ROI Align,生成同样大小的ROI以后再通过全连转化为vec,最后再通过fuse(文章中使用的fuse为max或者sum算子)生成唯一的vec用于类别和bbox的判定。
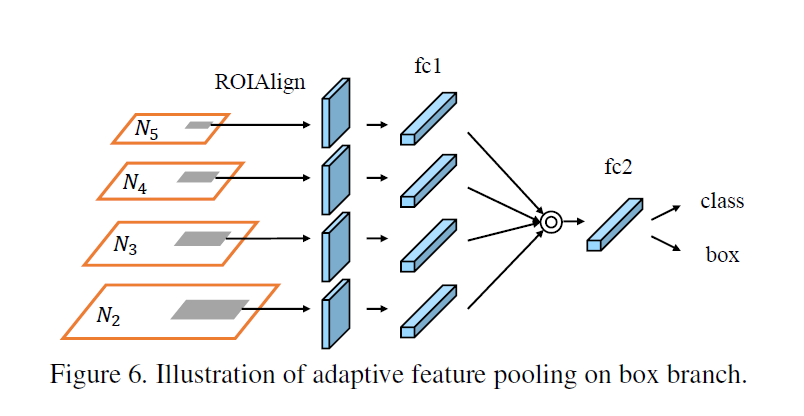
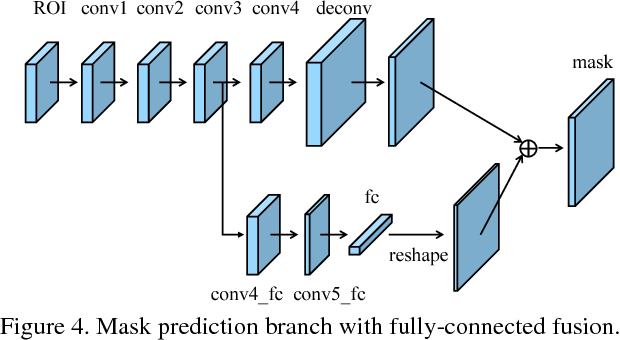
3.全连融合
做完自适应池化还没结束,由于我们想要完成的segmentation,还需要将各ROI的mask提取出来,这部分PANet依然沿用了Mask RCNN的思路。将池化提出的信息进行反卷后再以类别为channel做卷积。不同之处是PANet在mask进行卷积层中截取了一个分支进行全连操作,这个全连操作的目标是获得各mask的前景和背景的判断。从思路上看和Faster RCNN的FPN出来以后连接的全连非常相似,最终根据这个前背景判断的mask结合类别mask获得最终的结果。
4.最终效果
虽然只是一些小小的改进,但是从最终效果来看还是很明显的,这也秉承了深度学习的一贯特性:great improvement starts with small changes.

论文
以上只是论文的简单介绍,想要查看完整论文或者对中文不太感冒的同学,请移步至 Path Aggregation Network for Instance Segmentation